
VERTIPAQ
Jakto, že když nahraji svá data do Power BI, tak je výsledný soubor tak malý? Neměl by být stejně velký nebo větší než nahraná data?
Jakto, že když nahraji svá data do Power BI, tak je výsledný soubor tak malý? Neměl by být stejně velký nebo větší než nahraná data? To rozhodně ne. Kdyby tomu tak bylo, pak by byly všechny modely velmi velké a patrně bychom se jen velmi obtížně vešli do limitací na velikost datové sady pro Power BI Service. Naštěstí tu existuje něco, čemu se říká VertiPaq.
Představení Vertipaq(u)
Jde o ukládací nástroj, který je na pomezí Power BI a Power Query. Když v Power Query dochází k aplikování postupu a následnému nahrání dat do modelu, tak ve stejnou chvíli dochází ke zpracování dat právě pomocí tohoto nástroje. To, co vám toto okno pak oznamuje, je průběh, kdy se daná velikost tabulky převádí pomocí VertiPaqu do kompaktnější formy.

To jsme si řekli, co a kdy VertiPaq dělá. Ne však úplně přesně co, že je zač a jak to dělá.
Co je to VertiPaq
Jde o sloupcovou databázi, která se ukládá do paměti RAM. Dochází zde k její optimalizaci a uložení na disk, aby ji například Power BI mohlo využívat. Jako databázovou tabulku můžeme považovat seznam řádků, kde je každý řádek rozdělen do sloupců. Například tabulka produktů, jak je uvedeno níže.
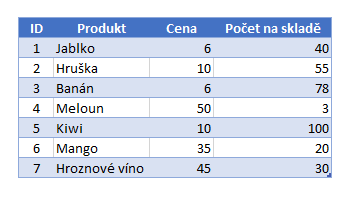
Co je sloupcová databáze?
Databáze, kdy jsou data organizována tak, aby byla optimalizována pro vertikální skenování. Toho lze docílit například rozseparováním řádků na samostatné sloupce.
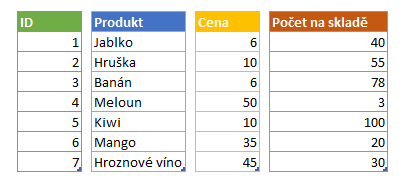
Při uložení dat ve sloupcové databázi má tedy každý sloupec svou vlastní datovou strukturu a ukládá se odděleně od ostatních sloupců. Hodnoty jednoho sloupce tak tedy přímo “nesousedí” s hodnotami ostatních sloupců. Při takovéto struktuře dat je výpočet součtu hodnot v jednotlivých sloupcích mnohem snazší. Dochází totiž k načtení celé tabulky sloupce a získání všech dat která jsou potřebná pro výpočet. Není tedy třeba číst hodnoty ostatních sloupců a ignorovat je, jak by tomu bylo, kdyby se jednalo o řádkovou databázi, kde jsou data uložená po řádcích. Příkladem takového záznamu v řádkové databázi pro nás mohl být například první řádek [1,“Jablko“,6,40]. V takovém případě bychom museli načíst celý řádek, procházet ho a ignorovat nepotřebné hodnoty jiných sloupců. Při jediném skenování sloupcové databáze získáte pouze užitečná čísla (za celý sloupec) a můžete je rychle agregovat bez nutnosti načítání a ignorování dat z ostatních sloupců.
Příklad získání výsledku ze sloupcové databáze
Kdybychom tedy chtěli znát počet položek na skladě, pak tedy snadno zjistíme, že výsledek je 326. Jak se tento algoritmus ale zachová, když řekneme, že chceme Počet položek na skladě, kde je Cena rovna číslu 10? Počítače takovou úlohu zpravidla řeší tak, že nejprve prohledají sloupec Cena. Tam, kde bude podmínka x = 10 splněna, tam si poznamenají čísla řádků, poté, co získají všechna čísla řádků, tak teprve prohledají sloupec Počet na skladě a sčítají pouze řádky, které si v předchozím kroku identifikovali.
Z toho vyplývá, že čím více omezení na výsledek je z pohledu ostatních sloupců, tím náročnější je získat výsledek. Avšak bez omezení je dosažení výsledku značně jednoduché.
Co krom rychlého čtení hodnot ve sloupci mi tato databáze poskytuje?
Sloupcové databáze mohou být velmi často pomocí komprese smrštěny, čímž dochází ke snížení množství času potřebného pro skenováním dat. Cílem algoritmů komprese VertiPaqu je zmenšit paměťovou stopu vašeho datového modelu.
Jak VertiPaq ukládá hodnoty sloupců do paměti?
Na to není jen jedna odpověď ale hned 3 (aby jich nebylo málo):
- Kódování hodnot
- Kódování slovníku
- RLE kódování.
Každý sloupec pak lze kódovat pomocí jedné z těchto technik.
Kódování hodnot
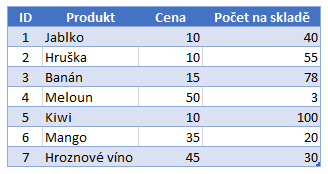
Kódování hodnot si můžeme ukázat na této tabulce. Je jen velmi mírně upravena oproti tabulce ze začátku. Vezmu-li si sloupec Cena, tak každé číslo ve sloupci představuje hodnotu, kterou je třeba uložit. Engine VertiPaq je velmi sofistikovaný a hledá matematické vztahy mezi hodnotami sloupce. V tomto případě je matematický vztah velmi jednoduchý. Můžete si všimnout, že všechny hodnoty jsou dělitelné číslem 5. Z toho důvodu VertiPaq celý sloupec vydělí tímto číslem, aby získal jednodušší hodnoty pro zakódování. Na malém počtu dat se takováto úprava může zdát nepatrná, ale na čím bude větší vzorek dat, tím větší bude i výsledné ušetření.
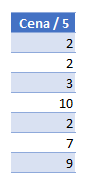
Takovéto kódování nám ale může zajistil optimálnější velikost pouze u sloupců obsahujících číselné hodnoty.
Kódování slovníku (Hash)
Kódování slovníku je další technikou používanou VertiPaq ke snížení počtu bitů potřebných k uložení sloupce. Vzniká slovník odlišných hodnot sloupce a poté nahradí hodnoty sloupců indexy do slovníku.
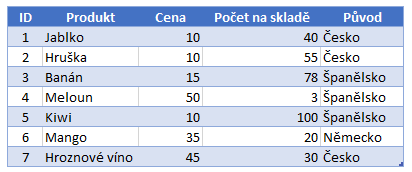
Pro vysvětlení na příkladu jsem rozšířil naši vstupní tabulku u Původ produktu. Při tomto kódování dojde tedy k vytvoření nové pomocné tabulky, která bude naším slovníkem a nahrazením původních hodnot pomocí indexu.
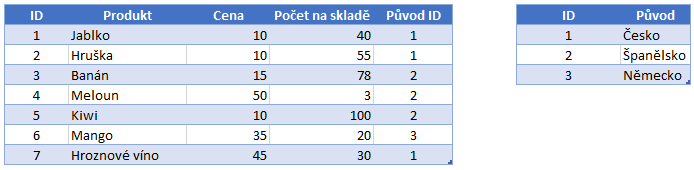
Takovéto zakódování sebou přináší určité výhody. Tou na první pohled zřejmou je ta, že textová hodnota, která vyžaduje větší počet bitů na zakódování se zbaví duplicit a je nahrazena indexem, který zabírá velmi malé množství bitů (v aktuálním případě stačí 2 bity). Dále pak sloupce obsahují pouze celé hodnoty, což usnadňuje optimalizaci, a navíc to v podstatě znamená, že VertiPaq je nezávislý na datovém typu.
Primárním faktorem pro určení velikosti sloupce při tomto kódování není typ dat, ale počet odlišných hodnot sloupce. Tato čísla (počet unikátních hodnot ve sloupci) označujeme jako mohutnost sloupce. Ze všech různých faktorů jednotlivého sloupce je nejdůležitějším při navrhování datového modelu jeho mohutnost. Čím nižší je mohutnost, tím menší je počet bitů potřebných k uložení jediné hodnoty, a tím menší je stopa paměti ve sloupci.
RLE kódování
RLE je bezeztrátová komprese, která kóduje vstupní data tak, že kóduje posloupnosti stejných hodnot do tří hodnot (hodnota, délka posloupnosti, index řádku, kde hodnota začíná). Účinnost komprese je silně závislá na charakteru vstupních dat, která musí obsahovat delší sekvence stejných znaků, jinak výrazně účinnost komprese klesá. K této kompresi VertiPaq přistupuje v případě, že objeví opakované výskyty těch samých hodnot ve sloupci.
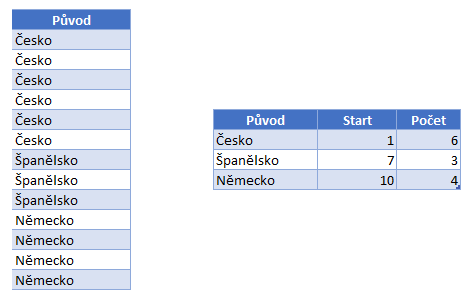
Jak se rozhoduje VertiPaq?
VertiPaq je velmi vychytralý nástroj, a ne vždy využije jen jednu ze zmíněných variant. Jeho primárním účelem je snížení datového objemu. Může tedy dojít i k tomu, že již zakódovaný sloupec pomocí slovníkového kódování bude ještě překódován kódováním RLE. Zároveň, pokud by z nějakého důvodu mělo kvůli průběhu kódování dojít ke zvýšení datového objemu, pak VertiPaq ponechá sloupec bez zakódování.
Kódují se tedy tabulky, které přicházejí do Power Query. Kóduje se ještě něco?
Ano, aby došlo k optimalizaci celkového výkonu, tak dochází i na kódování vazeb/vztahů, mezi tabulkami. Když probíhá načítání dat, tak se provádí tvorba vazeb v modelu. Přemýšleli jste někdy nad tím, jak jsou tyto vazby realizovány na pozadí, abyste dostali tak rychlou odpověď? Odpovědí je opět VertiPaq…
Při vytvoření vztahu buďto vámi nebo automaticky VertiPaq obdrží informaci, že tuto vazbu budete pravděpodobně používat často a pro zlepšení výkonu dotazů uloží vztahy jako dvojici ID (z jedné tabulky) a Čísla řádků (druhé tabulky) [vztah 1: n]. Výsledné vztahové tabulky jsou uloženy jako jakákoliv jiná datová struktura. Výsledný vztah nemusí aplikace dopočítávat při vyvolání podobně jako Measure ale má vazbu pevně uloženou v datovém modelu.








